Jika Anda mengikuti perkembangan di dunia AI, Anda pasti tahu bahwa perlombaan untuk menciptakan model paling canggih dan mampu bernalar biasanya didominasi oleh raksasa seperti OpenAI, Anthropic, dan Google. Tapi kini ada kejutan besar: sebuah perusahaan AI asal Tiongkok, DeepSeek, meluncurkan DeepSeek-R1—model reasoning open-source yang tidak hanya mampu bersaing dengan model OpenAI O1, tetapi juga mengesankan dengan performanya. Yang lebih mengejutkan? Model ini sepenuhnya open-source dengan lisensi MIT.
Apa Itu DeepSeek-R1?
DeepSeek-R1 adalah model reasoning yang dirancang untuk menangani tugas-tugas kompleks seperti matematika, pemrograman, dan penalaran logis. Bagian dari keluarga model DeepSeek, R1 melampaui model sebelumnya seperti DeepSeek-V3 yang sudah menjadi salah satu model open-source terbaik.
Yang membuat R1 berbeda adalah kemampuannya untuk menggunakan metode penalaran yang mirip seperti “berdialog dengan dirinya sendiri,” sebuah teknik yang dikenal sebagai test-time inference atau compute scaling. Model ini secara mandiri mengevaluasi masalah hingga mencapai jawaban terbaik.
Lebih menarik lagi, DeepSeek-R1 hadir dalam berbagai versi distilled, mulai dari 1,5 miliar hingga 70 miliar parameter. Salah satu versi kecilnya, DeepSeek-R1-Distill-Qwen-1.5B, bahkan mampu mengalahkan GPT-4 dalam beberapa benchmark. Bayangkan, model kecil yang dapat berjalan di perangkat sederhana mampu bersaing dengan teknologi mutakhir!
Kenapa Ini Penting?
1. Sepenuhnya Open-Source
DeepSeek-R1 dirilis dengan lisensi MIT, memungkinkan siapa pun untuk mengunduh, memodifikasi, fine-tune, atau bahkan melatih model baru berdasarkan R1. Hal ini berbeda jauh dengan ketentuan OpenAI yang melarang penggunaan output mereka untuk melatih model lain.
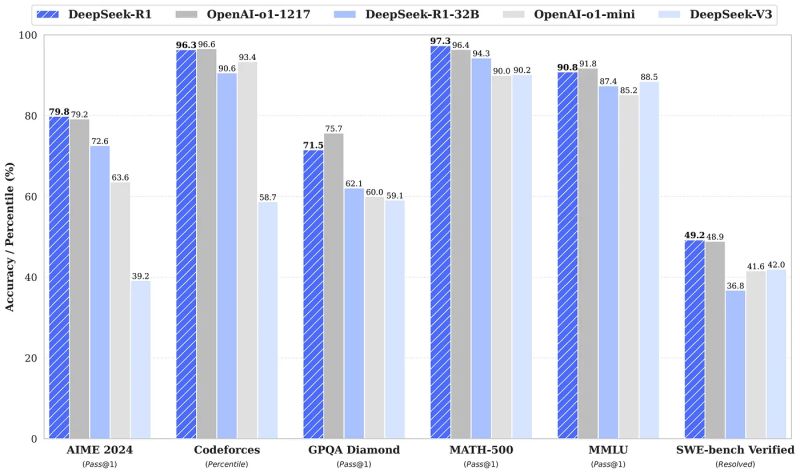
2. Sejajar dengan OpenAI O1
Berdasarkan benchmark, DeepSeek-R1 setara dengan O1 milik OpenAI dalam hal matematika, pemrograman, dan penalaran logis. Bahkan, model distilled-nya seperti DeepSeek-R1-Distill-Qwen-7B berhasil mencetak skor 55,5 pada benchmark AIME 2024, mengungguli GPT-3.5 dan Claude-3.5.
3. Metode Pelatihan Revolusioner
DeepSeek-R1 dilatih menggunakan Reinforcement Learning (RL) berskala besar tanpa bergantung pada supervised fine-tuning (SFT). Pendekatan ini memungkinkan model untuk mempelajari pola penalaran secara mandiri tanpa harus diberi data berlabel.
4. Cepat dan Aksesibel
Berbeda dengan beberapa model proprietary yang lambat atau sering mengalami downtime, DeepSeek-R1 sangat cepat dan gratis diakses melalui chat.deepseek.com. Mereka juga menyediakan API yang lebih murah dan tanpa batasan penggunaan.

